学术进展 | 我院刘聪、武振宇课题组合作研究开发大数据暴露组学分析工具
(供稿:郭毅)
近日,复旦大学公共卫生学院刘聪青年研究员与武振宇副教授研究团队在环境与健康暴露组学统计分析领域取得重要进展。研究团队通过对传统贝叶斯核机器回归(BKMR)方法进行加速与可解释性提升,为大规模人群研究和暴露组学数据分析提供了一种更高效、更可行的统计解决方案。该研究成果以“Advanced Bayesian Kernel Machine Regression for Large-Scale Exposome Studies: Making the Impossible Possible”为题,于2026年1月3日在国际知名期刊《The Innovation》在线发表,全文链接为https://www.cell.com/the-innovation/fulltext/S2666-6758(25)00451-5。
暴露组学研究通常涉及大量环境与行为因素,这些暴露变量之间常存在高度共线性与复杂交互关系。目前常用的分析方法包括可解释的统计模型(如lasso、WQS等)以及机器学习技术。前者需预设暴露与结局之间的函数形式,但模型假设一旦违背可能导致估计偏倚;后者虽具备强大的拟合能力且无需预设结构,但其“黑箱”特性限制了结果的可解释性。贝叶斯核机器回归(BKMR)兼具灵活建模能力与一定的可解释性,被视为暴露组学分析的有力工具,然而其计算复杂度高、运行效率低,难以应用于大规模数据,且在统计解释层面仍有不足。
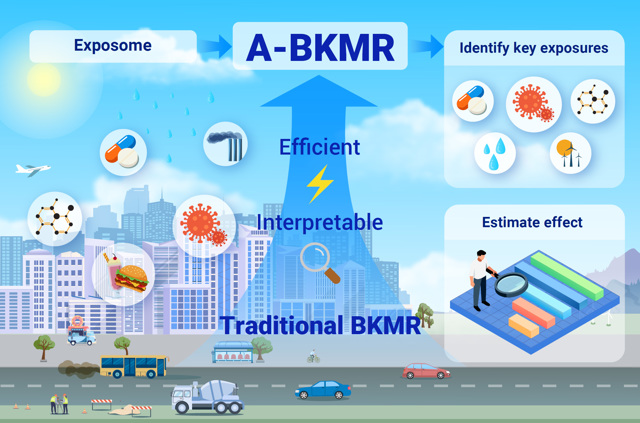
图1. A-BKMR 研究思路图
为解决上述问题,研究团队提出了先进BKMR方法(A-BKMR,图1)。该方法通过引入加权节点采样与高斯近似过程,显著降低了计算负担;进一步结合矩阵分解技术,避免直接生成高维矩阵,并全程调用Python实现高效运算,从而大幅提升运行速度(图2)。此外,研究团队基于g-formula框架开发了多种可解释统计量,包括联合效应、单变量效应及交互效应等,增强了结果解读的维度与深度。
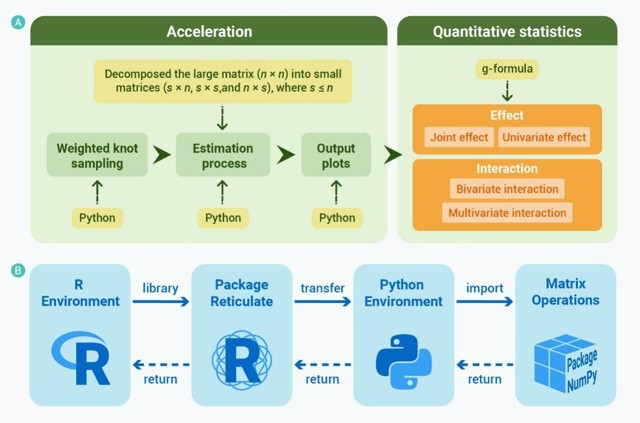
图2. A-BKMR工作流程图
研究显示,在样本量介于50至10万的模拟数据中,A-BKMR均能在一小时左右完成分析,而传统BKMR在样本量超过1万时即面临计算瓶颈部分加速BKMR(PA-BKMR)、并行BKMR版本(BKMRhat)及传统BKMR的计算时间随样本量增长呈近似指数上升,而A-BKMR仅呈现线性增长趋势(图3)。。后续测试进一步表明,A-BKMR在变量筛选与预测性能方面均表现优异。
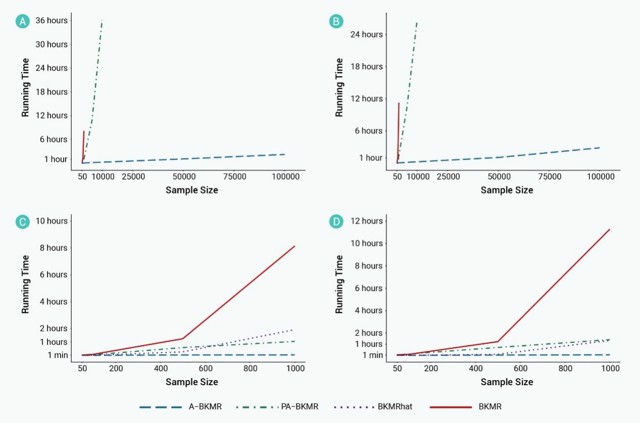
图3. 不同BKMR方法的运行时间
研究团队进一步在中国健康与营养调查(CHNS)和美国国家健康与营养调查(NHANES)数据中验证了该方法的实用性,成功估计了变量重要性、联合效应及交互效应等关键指标(图4)。
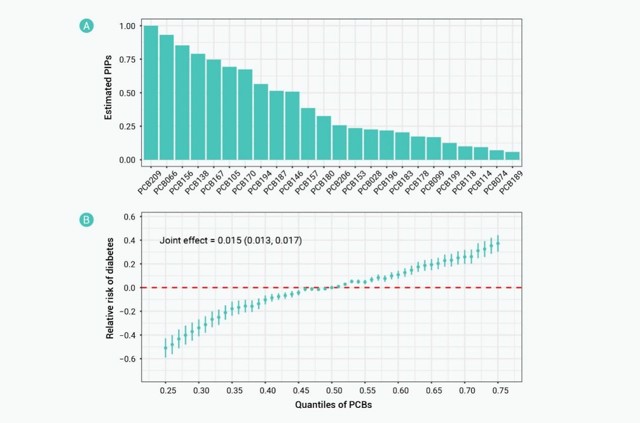
图4. NHANES案例研究中24种多氯联苯 (PCBs) 对糖尿病的重要性及其联合效应
A-BKMR不仅能准确识别暴露组中的关键变量,还具备优异的预测性能,同时提供丰富的可解释统计量,支持对多维度暴露效应的深入解析。为促进方法推广,研究团队已将A-BKMR封装为用户友好的R软件包,并提供详细教程与代码示例(https://github.com/Guo-yi-y/A-BKMR)。该方法广泛适用于环境混合暴露评估、营养摄入研究、生活方式分析等多个领域,并具备拓展至重复测量资料、中介分析及分布滞后非线性模型(DLNM)等复杂场景的潜力。目前,研究团队已基于A-BKMR开展多项环境因素混合暴露研究,最新进展可通过课题组GitHub页面(https://github.com/Guo-yi-y)或微信公众号获取。
复旦大学公共卫生学院博士生郭毅与上海市第一人民医院副研究员贾慧珣为本文共同第一作者,复旦大学公共卫生学院刘聪青年研究员与武振宇副教授为共同通讯作者。研究获国家自然科学基金(82422065、82173613、82373681、82471130)、上海市三年公共卫生行动计划(GWVI-11.2-YQ32)及国家重点研发计划(2022YFC2704604)等项目资助。
文章引用:Guo, Y., Jia, H., Peng, Z., Xu, X., Zhang, Z., Pan, K., Zhou, Y., Kan, H., Wu, Z., Liu, C., Advanced Bayesian Kernel Machine Regression for Large-Scale Exposome Studies: Making the Impossible Possible, The Innovation (2026), doi: https://doi.org/10.1016/j.xinn.2025.101248.